
私とCopilot+ PC
前回レッツノートSCのレビューで「今のところ、なんとしても手に入れたいCopilot+ PCの機能が一つも無いので困っていません」と書いたばかりなのですが、NPU活用という観点では、ローカルLLMには以前から大きな関心を寄せていました。
Copilot+ PCを手に入れたのが去年の今頃・・・CPUでもGPUでもなくNPUが搭載され、その性能が40TOPS以上。セキュリティやプライバシーを気にせず大手を振ってAI三昧と聞けば、嫌でも期待は大きくなります。これが実現できてこそAIの夜明けです。
しかし、実機を手にして早速トライしたものの、NPUを活用したローカルLLMに関する実用的な情報にはなかなかたどり着けませんでした。技術バリバリの方であれば実現できたのかもしれませんが、私のようなただのオッサンにはかなりハードルが高く感じられました。
「Copilot+ PCでローカルLLMが動く」という記事をまれに見かけても、その内容はLM StudioやVS Codeの拡張機能で動かすといったもので、対象はARMアーキテクチャのみ。
OSで提供されるCopilot+ PC向けの機能はどれも(私には)不要なものばかり。正直に言って「だまされた」と思いました。
来る日も来る日もCopilotさんに尋ね続けました。
Ryzen AI 7 PRO 360搭載のラップトップ、NPUを使ってローカルLLMできるようになりましたか?
こんなことを繰り返しながら「もう疲れたよ、パトラッシュ」と化した私は、身辺が慌ただしくなった時期と重なったこともあって、ローカルLLMという言葉からしばし遠ざかることになりました。
諦めたらそこで終わり
状況が一転したのは今月で、たまたま見つけた先人の記事。
AMDの第2世代NPUで動作するLLM基盤に衝撃を受けて興奮が止まらないお話 #Windows – Qiita
記事の公開日は8月。なんと!私が別件で右往左往していた夏の間に状況が変わっていたようで、鼻息荒く早速やってみました。
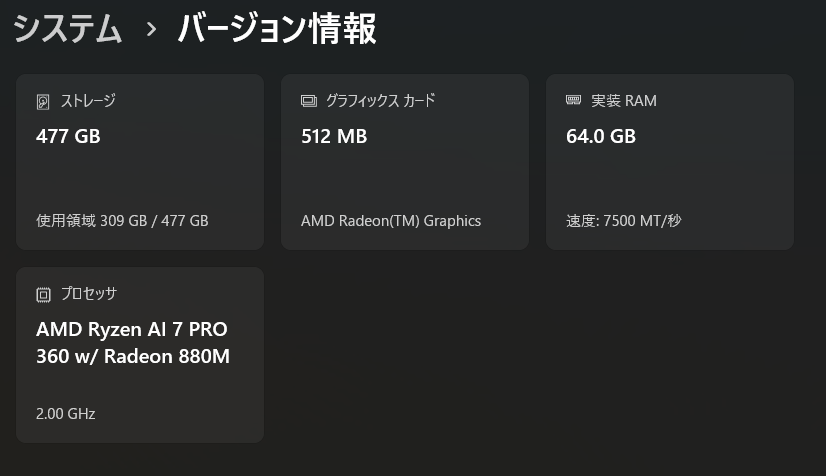
検証機スペック
ThinkPad T14s Gen6、OSはWindows 11 Pro 24H2です。セールのタイミングだったのと、営業さんとの交渉でかなり安価に入手できました。
余談ですが、このマシンはアイキャッチ画像にしているもので、スキンシールはPDA工房さま製です。パームレスト部分もオーダーで作っていただいた同素材のものを貼っていて、とても気に入っています。
構築手順
まずはNPUドライバーのバージョンを確認しましょう。「FastFlowLM」のQuick Startにはこのようにあります。
Important
⚠️ Ensure NPU driver verison is >= 32.0.203.311 (check via Task Manager→Performance→NPU or Device Manager).
デバイスマネージャーをチェックしましょう。
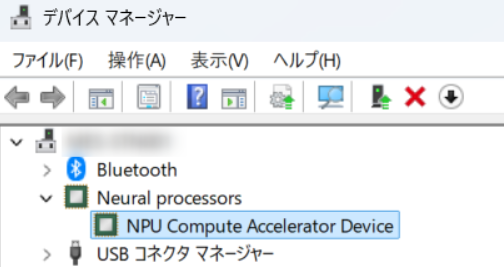
こちらはアップデート後のキャプチャです。
FLMのインストーラーをダウンロードします。なお、FLMはライセンスが2つに分かれており、ランタイム部分はMIT、バイナリ部分は「FastFlowLM Proprietary Binary License Agreement」となっています。年間収益1000万米ドルまでは商用ライセンス不要で、米国デラウェア州法が適用されます。利用前に必ずご自身で内容を確認ください。
FastFlowLMのインストーラーをダウンロードしましょう。

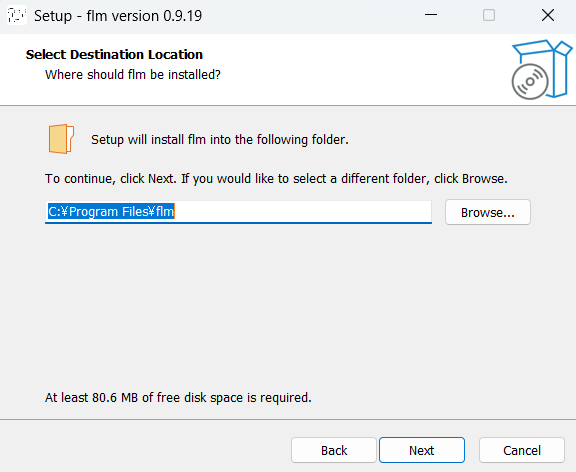
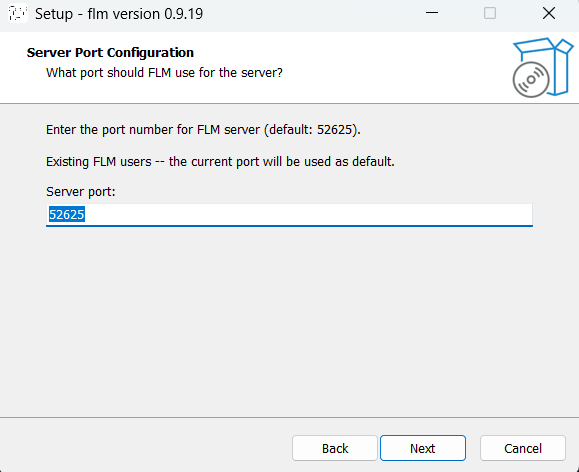
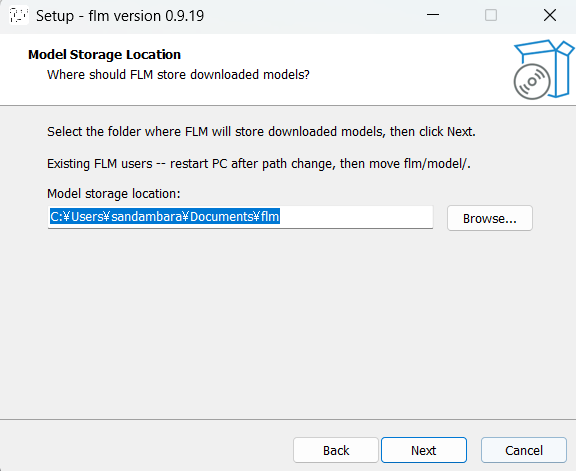
インストーラーを実行します。ボタンポチポチだけで大丈夫です。
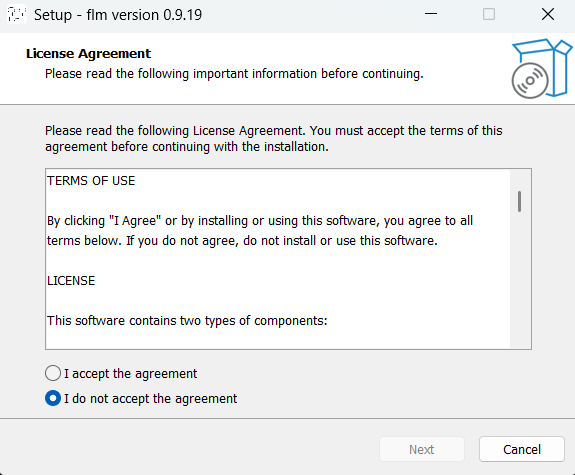
↑いうまでもありませんが、I accept the agreementを選んでくださいね・・・
ここまででFLMを使う準備は整っていますが、Lemonadeがあるとさらに簡単に使えますのでインストールしましょう。GitHubのリポジトリはこちら。

NPU、AMD Ryzen AI 300 series。この文字が見られる日を待ちわびておりました。
では、インストーラーをダウンロードしましょう。
こちらもボタンポチポチで進めていきます。
ポップアップが見えたらLemonade起動完了です。これで準備が整いました。
いよいよローカルLLMとご対面!
せっかくなら少しでも性能の良いモデルを試してみたいので、ここではgpt-oss-20bを動作させることを目標に進めていきます。
FLMのインストールが終わったときに、デスクトップへアイコンが2つ作られています。このうち「flm serve」をダブルクリックして実行します。
コマンドプロンプトが起動し、デフォルトモデルのllama3.2:1bのダウンロードが始まります。
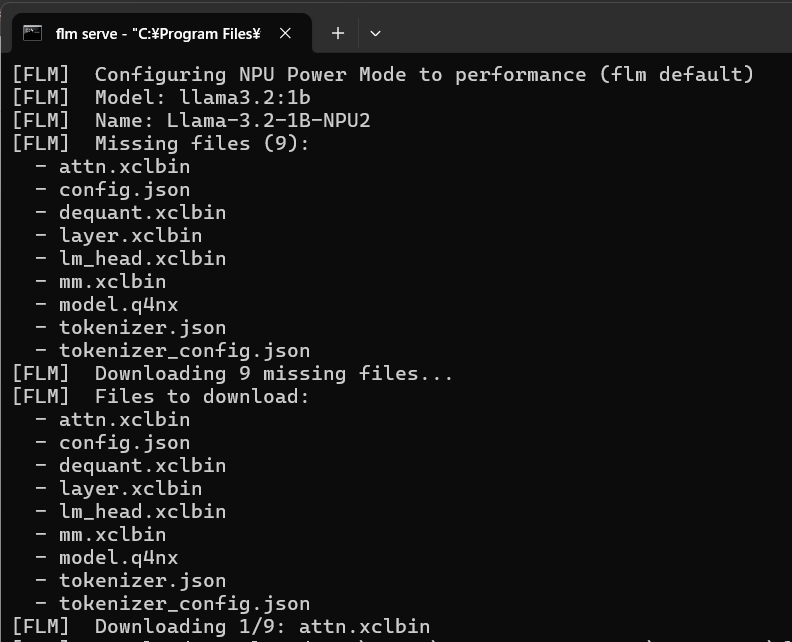
軽量モデルですので直ぐにダウンロードは終了し、FLMの準備が整います。このコマンドプロンプトは開いたままにしておきましょう。

次に、タスクトレイにあるLemonadeのアイコンを右クリック→Model Managerを選択します。
ブラウザが起動しlocalhost:8000/webapp.html#model-managementが表示された、左ペインにある「FastFlowLM NPU」を選択します。
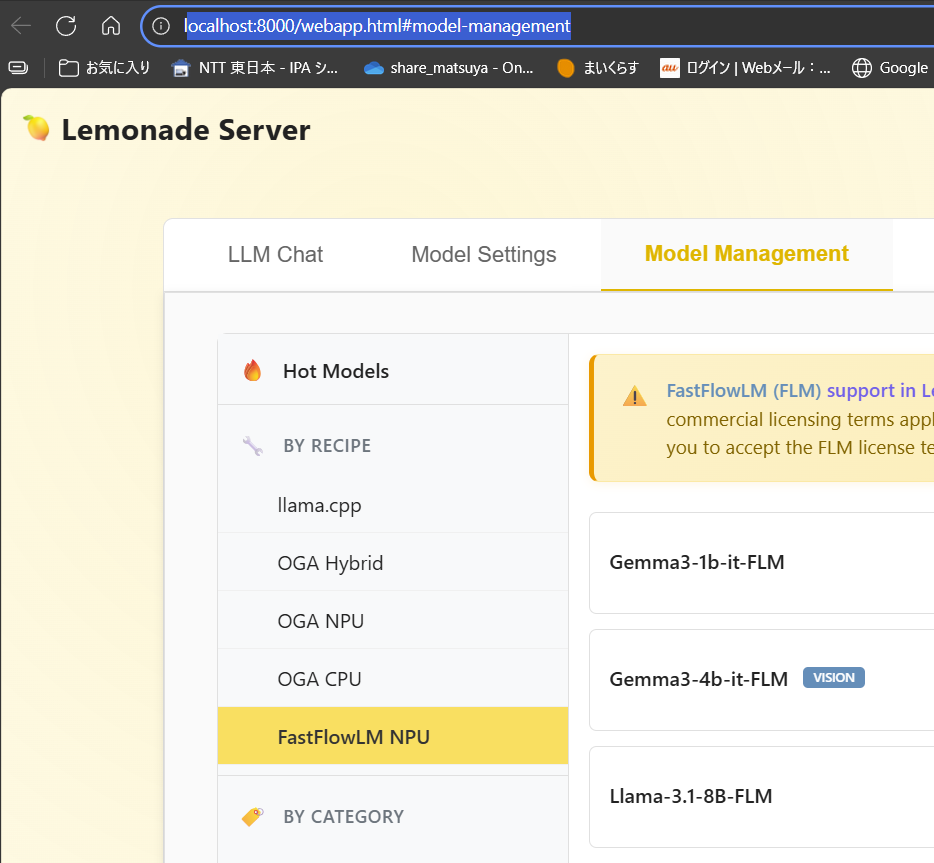
右ペインからgpt-oss-20b-FLMを探し、下向き矢印のアイコンをクリックしてモデルをダウンロードしましょう。インストーラーをデオフォルトで進めた場合はドキュメントにモデルが保存されます。

ダウンロードが完了するとモデルを起動するロケット?のアイコン、モデルを削除するゴミ箱のアイコンが表示されます。

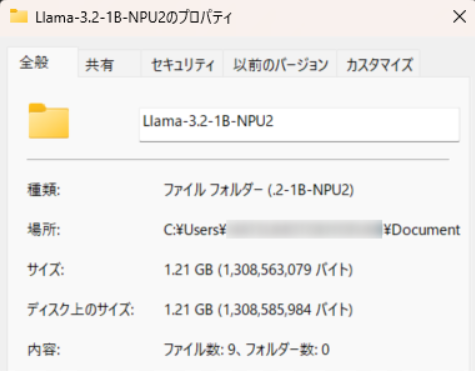
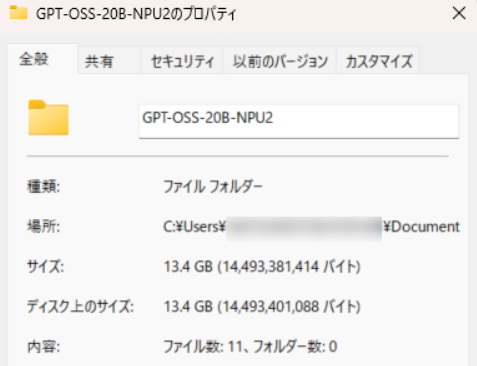
参考までに、llama-3.2-1B-NPU2が保存されたフォルダのサイズが1.21GBに対し、GPT-OSS-20B-NPU2が保存されたフォルダのサイズは13.4GBでした。脳ミソは大きい方が高性能ということでしょうか。
では、先ほどのロケット?のアイコンをクリックしてからLLM Chatへ移動します。右上のモデルがgpt-oss-20b-FLMになっています。
ここでは「あなたはローカルLLMで、利用時はインターネット接続不要ですか?また、あなたはどのように私を助けてくれますか?できるだけ正確に答えてください。」と聞いてみます。タスクマネージャーでNPUのゲージが動くことも見逃せません。
いかがでしょうか。大規模言語モデルが目の前のラップトップで動いている・・・なんたるロマン。ようやくAIの夜明けを迎えた気分です。
他と比べてどうか
性能や応答速度をChatGPTやClaude、CopilotといったクラウドAIと比べるのは、そもそもの機材スペックがどれだけ違うかという話なので、比べること自体がナンセンスであります。
では、たとえばMacと比べるとどうかと言われれば、同じ質問で試して4倍弱時間がかかっています。ollama+gpt-oss-20bをメモリ24GBのM4 Proで動作させるとこんな感じです(こちらはCLIで動かしていますので、比較では無く参考ということで)。アクティビティモニタの値もなんとなく見てみます。
個人的に思うことは以下の通りです。
- 出力速度は確かに速いが、速すぎて見づらい感ある
- Copilot+ PCはNPUのさらなる高性能化を期待
- Appleシリコンすごい
まとめ
比べれば遅いとはいえCopilot+ PCでNPUを使ったローカルLLM、十分実用的な速度で動作していると思います。ちなみに、先ほどの動画収録時の電源とバッテリー設定は「最適な電力効率」で、ファンもほぼ回らず静かなまま。NPUってやっぱりすごいんだなあと思います。餅は餅屋です。
かつてと比べればMac環境も増えたけれど、世の中のシェアでいえば圧倒的に多いWindowsユーザーの選択肢が増えたこと、これは普通にうれしいです。もっともっとこういうことが簡単にできるようになると良いですね。夜は明けたので、陽が昇るのはこれからかな?

コメント